| CPC G06F 40/44 (2020.01) [G06F 9/30196 (2013.01); G06F 18/214 (2023.01); G06F 40/30 (2020.01); G06F 40/40 (2020.01); G06N 3/08 (2013.01)] | 15 Claims |
|
1. A translation model training method for a computer device, comprising:
obtaining a training sample set, the training sample set including a plurality of training samples, wherein each training sample is a training sample pair having a training input sample in a first language and a training output sample in a second language;
determining a disturbance sample set corresponding to each training sample in the training sample set, the disturbance sample set comprising at least one disturbance sample, and a semantic similarity between the disturbance sample and the corresponding training sample being greater than a first preset value, wherein the disturbance sample set includes: a disturbance input sample set corresponding to each training input sample, and a disturbance output sample which is the same as the training output sample; and
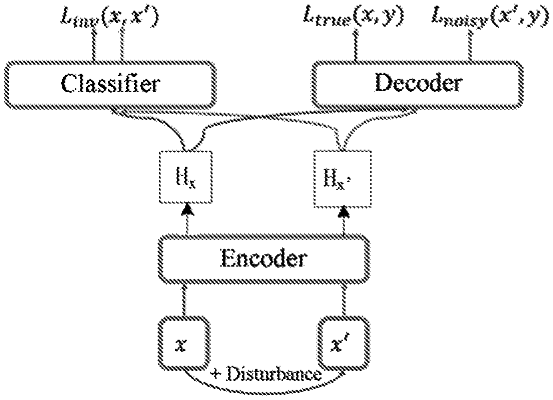
training an initial translation model by using the plurality of training samples and the disturbance sample set corresponding to each training sample to obtain a target translation model, wherein the initial translation model comprises:
an encoder configured to receive the training input sample from the training sample set and a corresponding disturbance input sample from the disturbance sample set, and output a first intermediate expressed result and a second intermediate expressed result, the first intermediate expressed result being an intermediate expressed result of the training input sample, and the second intermediate expressed result being an intermediate expressed result of the corresponding disturbance input sample;
a classifier is configured to distinguish the first intermediate expressed result from the second intermediate expressed result, and
a decoder is configured to output the training output sample according to the first intermediate expressed result and output the training output sample according to the second intermediate expressed result.
|