| CPC G06F 40/35 (2020.01) [G06F 16/532 (2019.01); G06F 40/40 (2020.01); G06V 10/764 (2022.01); G06V 10/774 (2022.01); G06V 10/803 (2022.01); G06V 10/82 (2022.01); G06V 10/96 (2022.01)] | 20 Claims |
|
1. A method implemented via execution of computing instructions by one or more processors and stored on one or more non-transitory computer-readable storage devices, the method comprising:
providing a multi-modal application that includes:
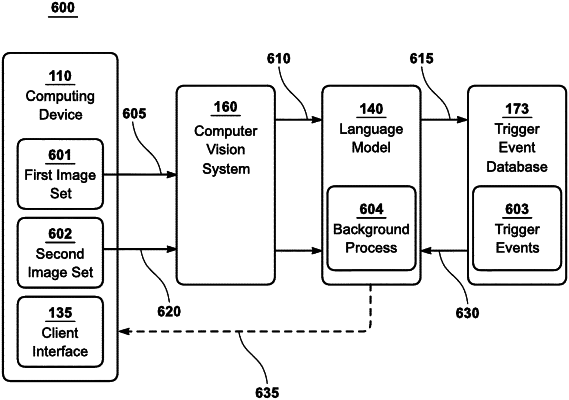
a computer vision system configured to execute one or more computer vision tasks and generate computer vision outputs; and
a client interface that facilitates interactions between an end-user and a language model that generates language model outputs for communicating with the end-user;
executing, using the computer vision system, at least one computer vision task on an image to generate a computer vision output;
comparing the computer vision output generated by the computer vision system with one or more trigger events;
in response to detecting a match between the computer vision output and the one or more trigger events, executing, by the language model, at least one natural language processing (NLP) task to generate a preemptive output; and
outputting the preemptive output via the client interface.
|