| CPC G06F 40/247 (2020.01) [G06F 40/268 (2020.01); G06F 40/279 (2020.01)] | 3 Claims |
|
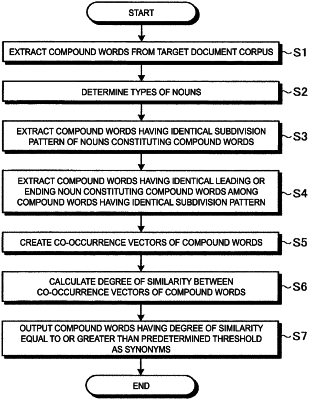
1. A synonym extraction apparatus comprising:
a determination unit, including one or more computers, configured to determine, for compound words included in a document, that types of nouns constituting a compound word of the compound words are each a Sahen-noun or a noun other than a Sahen-noun;
a first extraction unit, including one or more computers, configured to extract, from among the compound words included in the document, a first group of compound words having an identical pattern of a sequence of the determined types of the nouns constituting the compound word, based on a determination result of the types of nouns constituting the compound word;
a second extraction unit, including one or more computers, configured to extract a second group of compound words having an identical leading or ending word from the first group of compound words having the identical pattern of the sequence of the determined types of the nouns;
a co-occurrence vector creation unit, including one or more computers, configured to create, for each compound word of the second group of compound words extracted by the second extraction unit, a co-occurrence vector having, as a vector component, a noun co-occurring in a same sentence as a sentence including the compound word;
a similarity degree calculation unit, including one or more computers, configured to calculate, for each compound word of the second group of compound words extracted by the second extraction unit, a degree of similarity between the created co-occurrence vectors; and
an output unit, including one or more computers, configured to output to a display device, as synonyms, a third group of compound words having the degree of similarity between the created co-occurrence vectors equal to or greater than a predetermined threshold,
wherein for each compound word of the group of compound words extracted by the second extraction unit,
the co-occurrence vector creation unit is further configured to create, for a character string obtained by adding a case particle between nouns constituting the compound word, a first co-occurrence vector of the compound word having, as a vector component, a noun co-occurring in a same sentence as a sentence including the character string, and create a second co-occurrence vector of the compound word by adding the first co-occurrence vector of the compound word created to the co-occurrence vector of the compound word, and
the similarity degree calculation unit is configured to calculate a degree of similarity between the second co-occurrence vectors of the compound words as the degree of similarity between the created co-occurrence vectors of the compound words.
|