| CPC G06F 16/334 (2019.01) [G06F 16/335 (2019.01); G06F 40/295 (2020.01)] | 20 Claims |
|
1. A system comprising:
one or more hardware processors; and
a non-transitory memory storing computer-executable instructions, that in response to execution by the one or more hardware processors, causes the system to perform operations comprising:
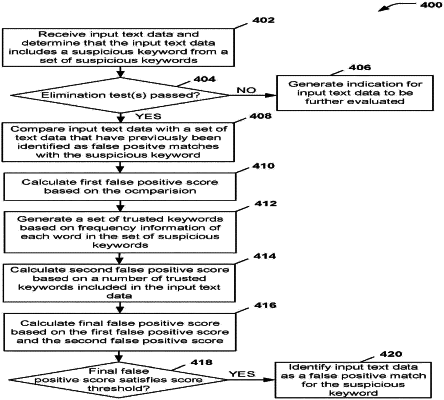
in response to receiving text data that corresponds to an Internet search, determining at least a portion of the text data is included in a first set of keywords previously identified by the system;
calculating a first false positive score associated with the text data, wherein the first false positive score is calculated at least in part by comparing the text data to a plurality of text strings that contain one or more keywords from the first set of keywords, and wherein the plurality of text strings were previously determined to be false positive;
determining a set of trusted keywords using at least a frequency score, wherein the frequency score is determined based at least in part on a frequency of each word of the plurality of text strings appearing in the plurality of text strings that were previously determined to be false positive;
calculating a second false positive score associated with the text data, wherein the second false positive score is calculated based in part on a number of times a word from the set of trusted keywords is included in the text data;
identifying, based on the first false positive score and the second false positive score, the text data as a match to a result type; and
determining, based on the identifying, whether one or more webpages containing the text data should be returned as a result of the Internet search.
|