| CPC G06F 16/24568 (2019.01) [G06F 16/2228 (2019.01)] | 29 Claims |
|
1. A method comprising:
obtaining, by an edge device and from one or more sensor devices, a plurality of data streams corresponding to objects, activities, or events registered in an edge environment associated with the edge device;
generating, using one or more machine learning networks implemented on the edge device, a plurality of features corresponding to each respective data stream of the plurality of data streams and different data types of the plurality of data streams;
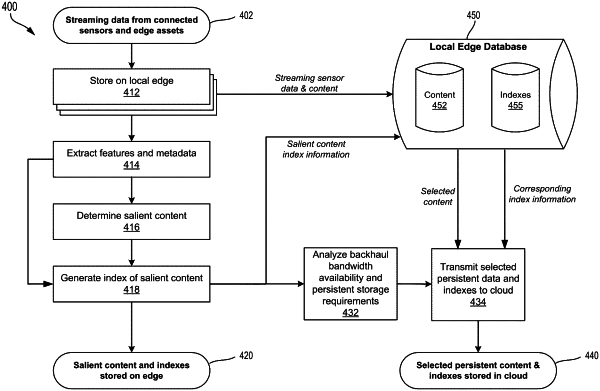
determining, by the edge device, a subset of salient content from the plurality of data streams, wherein the subset of salient content is determined based on analyzing the plurality of features to identify duplicate data streams having similar features as respective features of a previously indexed and stored data streams, and wherein the subset of salient content is generated without duplicate data streams;
generating, by the edge device, index information corresponding to the determined subset of salient content, wherein the index information is generated based on two or more of feature extraction, embedding generation, and tokenization performed for the plurality of data streams, and wherein the index information comprises an inverse index including inverse index keys of the subset of salient content;
storing, without using cloud connectivity the subset of salient content and the generated index information locally at the edge device for search and retrieval based on local queries received at the edge device, wherein the subset of salient content is stored based on bandwidth availability between the edge device and a cloud entity;
receiving, by the edge device, a local query for the stored subset of salient content; and
in response to the receiving the local query, processing the local query against the generated index information by:
determining one or more inverse index keys of the inverse index keys corresponding to search terms represented in the local query; and
determining a respective relevance score for pieces of the stored subset of salient content mapped to the determined one or more inverse index keys of the inverse index keys; and
outputting corresponding identifiers of the pieces of the stored subset of salient content with the respective relevance score greater than a configured threshold.
|