| CPC G06F 15/7825 (2013.01) [G06F 9/4881 (2013.01); G06F 9/5027 (2013.01); G06F 9/54 (2013.01); G06F 15/7821 (2013.01); G06F 15/7842 (2013.01)] | 20 Claims |
|
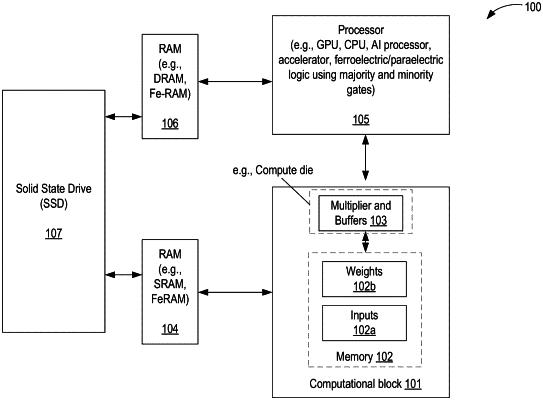
1. An apparatus comprising:
a processor core coupled to an accelerator core via an interconnect; and
a first memory coupled to the processor core, wherein the accelerator core is coupled to a second memory, wherein the processor core is to fetch an instruction and to determine whether the instruction is to be scheduled for processing by the processor core of a compute die or the accelerator core of an accelerator die based on a type of the instruction, wherein the processor core is to assemble the instruction in a command packet that includes data address associated with the second memory, and to send the command packet to the accelerator core via the interconnect, and wherein the processor core and/or the accelerator core includes ferroelectric logic.
|