| CPC G06F 12/1018 (2013.01) [G06F 16/2255 (2019.01); G06F 16/273 (2019.01); G06F 16/30 (2019.01); G06F 16/325 (2019.01); G06F 2212/152 (2013.01); G06F 2212/656 (2013.01)] | 19 Claims |
|
1. A method for performing a deduplication operation in a computer system having multiple host computer systems connected to a common storage system, the method comprising:
at each host computer system, tracking write operations to the common storage system, the write operations comprising a first write operation; and
performing the deduplication operation on storage blocks associated with the write operations by using a data structure to find duplicate blocks, the data structure comprising:
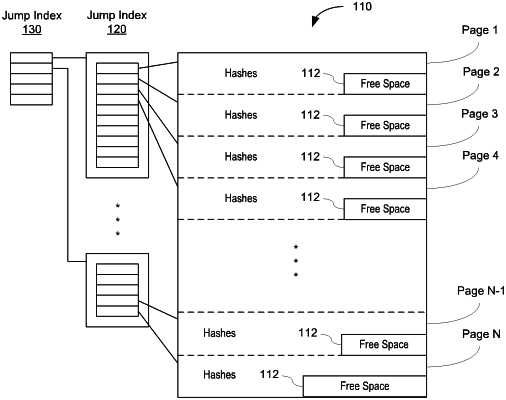
a hash index that is divided into a plurality of pages, each of the plurality of pages including one or more entries of the hash index, each entry of the hash index containing (a) a hash value of a block stored in the common storage system and (b) a file pointer associated with the block, wherein the entries of the hash index are maintained in sorted order according to the hash values of the entries of the hash index; and
one or more jump indexes, each of the one or more jump indexes including a corresponding plurality of entries, each of the corresponding plurality of entries including (a) a hash value of a first entry of a corresponding page of the plurality of pages of the hash index and (b) a pointer to the corresponding page;
wherein performing the deduplication operation on storage blocks associated with the write operations by using the data structure comprises:
generating a first hash value of a data block of the first write operation;
associating the first hash value with a first file pointer derived from the first write operation;
determining the first hash value is not in the hash index;
locating an entry in the one or more jump indexes including a second hash value associated with the first hash value;
locating a first page of the hash index using a first pointer included in the entry in the one or more jump indexes; and
adding a new entry to the first page of the hash index, the new entry containing the first hash value and the first file pointer.
|