| CPC G06F 11/0709 (2013.01) [G06F 16/215 (2019.01); G06F 16/2358 (2019.01); G06F 16/278 (2019.01); G06F 16/9024 (2019.01)] | 18 Claims |
|
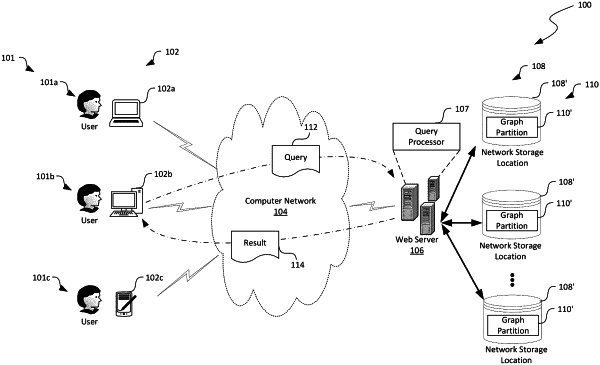
1. A method for reproduction of graph data in a distributed computing system having multiple servers hosting a query processor configured to query a graph having a first partition interconnected to a second partition, the method comprising:
receiving, at the query processor in the distributed computing system, a query to be evaluated on data in the graph; and
in response to receiving the query, with the query processor,
converting the received query into a set of predicates for evaluation;
evaluating each of the set of predicates based on data in the first or second partition of the graph, where evaluating the set of predicates includes detecting a query error, the query error caused by at least one of logic corruption, missing data, duplicate data or other data inconsistency in the first or second partition of the graph;
recording a sequence of query states of the first or second partition whose data is used to sequentially evaluate the each of the set of predicates by:
detecting for evaluation one of the set of predicates on the data in the first or second partition;
upon detecting that one of the set of predicates is to be evaluated on the data in the first or second partition, recording information of presence and relationship of data items in the first or second partition; and
anonymizing the recorded information of the presence and relationship of the data items in the first or second partition as one of the query states; and
subsequently, upon detecting a query error during evaluation of the set of predicates,
constructing a set of snapshots of the data in the first or second partition of the graph based on the recorded sequence of query states; and
reevaluating the set of predicates on the constructed set of snapshots of the data in the first or second partition to troubleshoot the detected query error when the set of predicates were previously evaluated.
|