| CPC B25J 9/161 (2013.01) [B25J 9/163 (2013.01); B25J 9/1664 (2013.01); G05B 13/027 (2013.01); G05B 19/042 (2013.01); G06N 3/008 (2013.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G05B 2219/32335 (2013.01); G05B 2219/33033 (2013.01); G05B 2219/33034 (2013.01); G05B 2219/39001 (2013.01); G05B 2219/39298 (2013.01); G05B 2219/40499 (2013.01)] | 20 Claims |
|
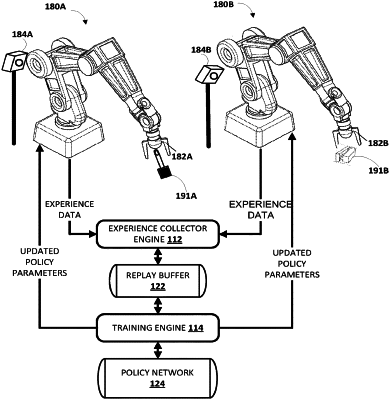
1. A method implemented by one or more processors, comprising:
receiving a given instance of robot experience data generated by a given robot of a plurality of robots, wherein the given instance of the robot experience data is generated during a given episode of explorations of performing a task based on a given version of policy parameters of a policy network utilized by the given robot in generating the given instance;
receiving additional instances of robot experience data from additional robots of the plurality of robots, the additional instances generated during episodes, by the additional robots, of explorations of performing the task based on the policy network;
while the given robot and the additional robots continue the episodes of explorations of performing the task, generating a new version of the policy parameters of the policy network based on training of the policy network based at least in part on the given instance and the additional instances;
providing the new version of the policy parameters to the given robot for performing of an immediately subsequent episode of explorations of performing the task by the given robot based on the new version of the policy parameters.
|