| CPC H04N 7/157 (2013.01) [G06T 7/246 (2017.01); G06T 7/73 (2017.01); G06T 17/20 (2013.01); G06V 40/10 (2022.01); G06V 40/166 (2022.01); G06V 40/171 (2022.01); G06V 40/172 (2022.01); G10L 19/167 (2013.01); G06T 2200/24 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/30201 (2013.01)] | 20 Claims |
|
1. A method for video conferencing comprising:
during a setup period:
accessing a target image of a first user;
detecting a target face in the target image;
representing a target constellation of facial landmarks, detected in the target image, in a target facial landmark container;
initializing a target set of face model coefficients;
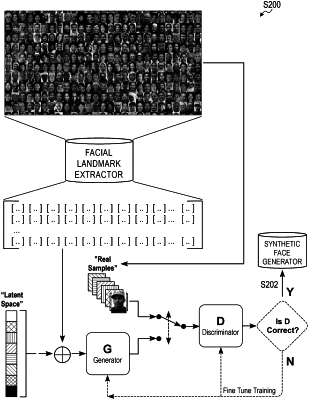
generating a synthetic test image based on the target facial landmark container, the target set of face model coefficients, and a synthetic face generator;
characterizing a difference between the synthetic test image and the target face detected in the target image;
adjusting the target set of face model coefficients to reduce the difference; and
generating a first face model, associated with the first user, based on the target set of face model coefficients; and
during an operating period succeeding the setup period:
accessing a first frame depicting the first user;
detecting a first constellation of facial landmarks in the first frame; and
representing the first constellation of facial landmarks in a first facial landmark container; and
generating a first synthetic face image based on the first facial landmark container, the first face model, and the synthetic face generator.
|