| CPC H04L 67/1076 (2013.01) [G06N 3/045 (2023.01); G06N 20/00 (2019.01); H04L 49/15 (2013.01); H04L 45/08 (2013.01)] | 18 Claims |
|
1. A method comprising:
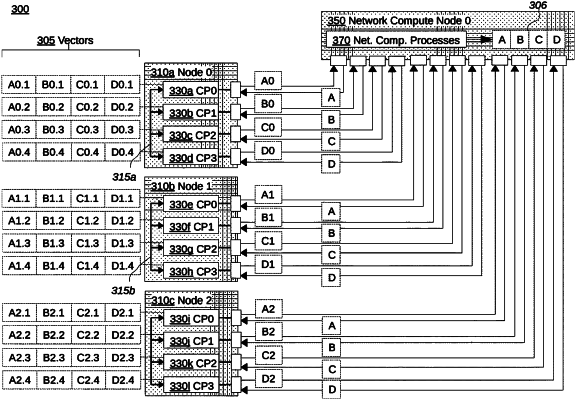
receiving, by a network switch implemented at least in part with one or more hardware processors, vector chunks over a plurality of switch ports;
wherein the vector chunks have values generated by a plurality of compute nodes for a common set of vector elements;
wherein the common set of vector elements includes a plurality of subsets of vector elements;
wherein each vector chunk of the vector chunks is received over a respective switch port, of the plurality of switch ports, from a respective compute node in the plurality of compute nodes;
wherein said each vector chunk has a subset of the values for a respective subset in the plurality subsets of vector elements;
reducing, by the network switch, the vector chunks generated by the plurality of compute nodes into a single result chunk;
sending, by the network switch, the single result chunk to each compute node of the plurality of compute nodes.
|