| CPC H04L 43/045 (2013.01) [G06F 9/5072 (2013.01); G06F 11/3006 (2013.01); G06F 11/327 (2013.01); G06F 11/3433 (2013.01); G06F 11/3452 (2013.01); G06F 21/41 (2013.01); H04L 43/06 (2013.01); H04L 43/0876 (2013.01); G06F 3/04847 (2013.01); G06F 2201/815 (2013.01); G06F 2209/508 (2013.01); G06F 2221/2137 (2013.01)] | 20 Claims |
|
1. A method comprising:
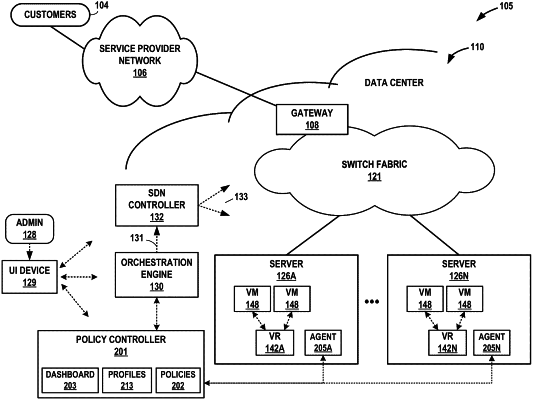
enabling, by a controller, a plurality of policy agents to monitor usage metrics for each of a first plurality of compute nodes within a first compute cluster and to monitor usage metrics for each of a second plurality of compute nodes within a second compute cluster;
receiving, by the controller and from the plurality of policy agents, information about the usage metrics for the first plurality of compute nodes and information about the usage metrics for the second plurality of compute nodes;
evaluating, by the controller and based on the information about the usage metrics for the first plurality of compute nodes, infrastructure elements for the first compute cluster;
evaluating, by the controller and based on the information about the usage metrics for the second plurality of compute nodes, infrastructure elements for the second compute cluster;
generating, by the controller, health data including first health status information for the infrastructure elements for the first compute cluster and second health status information for the infrastructure elements for the second compute cluster;
outputting, by the controller, a first single-cluster user interface for presentation as a single-cluster dashboard for the first compute cluster, wherein the first single-cluster user interface presents the first health status information but not the second health status information; and
outputting, by the controller, a second single-cluster user interface for presentation as a single-cluster dashboard for the second compute cluster, wherein the second single-cluster user interface presents the second health status information but not the first health status information.
|