| CPC G16H 50/20 (2018.01) [G06F 40/30 (2020.01); G06N 3/045 (2023.01); G06N 3/047 (2023.01); G06N 3/08 (2013.01); G06V 30/18 (2022.01); G06V 30/413 (2022.01); G16H 10/20 (2018.01); G16H 10/40 (2018.01); G16H 10/60 (2018.01); G16H 70/20 (2018.01)] | 19 Claims |
|
1. A method comprising,
receiving scanned documents, wherein the scanned documents comprise unstructured data;
performing optical character recognition of the scanned documents to produce text data for each page of the scanned documents, wherein the text data for each page comprises a sequence of words stored together with their location as x, y coordinates;
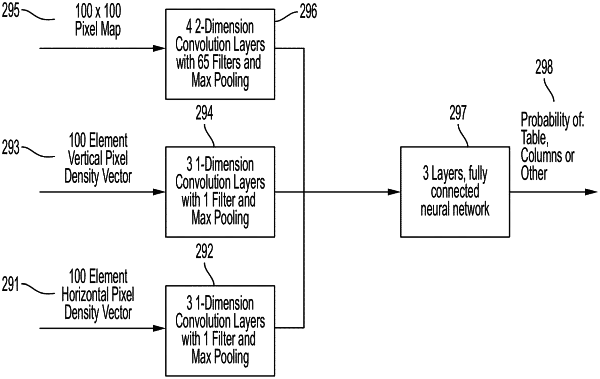
dividing each page of the scanned documents into subsections, wherein the dividing each page into subsections comprises applying a page blocker, wherein the page blocker identifies vectors of pixel density in the vertical and horizontal direction to identify vertical and horizontal page breaks;
using the text data to identify a structure type of each subsection of a page, wherein the structure type includes at least one of a table and text paragraph, wherein the identifying a structure type includes applying a structure classifier, wherein the structure classifier comprises a multi-stage neural network that assigns a probability of structure type to each subsection of a page;
using the text data to label each subsection of a page with a semantic type, wherein the semantic type defines a context surrounding collection of information in a subsection; and
using the text data for each subsection of a page to identify medical concepts.
|