| CPC G10L 25/66 (2013.01) [A61B 5/16 (2013.01); A61B 5/4803 (2013.01); A61B 5/7267 (2013.01); A61B 5/7282 (2013.01); G10L 17/00 (2013.01); G10L 25/18 (2013.01); G10L 25/63 (2013.01); G10L 25/90 (2013.01)] | 17 Claims |
|
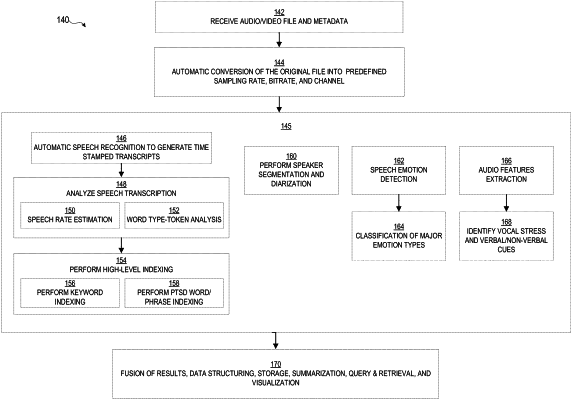
1. A computer-enabled method for obtaining a diagnosis of a mental health disorder or condition, the method comprising:
receiving an audio input;
sampling the received audio input by one or more microphones to generate an electrical audio signal;
converting the audio signal into a text string;
identifying a speaker associated with the text string;
detecting an indicator of the mental health condition based on a portion of the text string, wherein detecting the indicator of the mental disorder or condition comprises:
applying a machine learning classifier to the portion of the text string and generating from the classifier an indicator of the mental health condition, wherein the machine learning classifier includes a neural network generated using training data, the training data comprising a plurality of audio inputs previously associated with a known mental health condition;
determining, based on at least a portion of the audio signal, a predefined audio characteristic of a plurality of predefined audio characteristics, wherein determining the predefined audio characteristic comprises determining one or more electrical properties of the electrical audio signal;
identifying, based on the determined audio characteristic of the plurality of predefined audio characteristics corresponding to the portion of the audio input, an emotion corresponding to the portion of the audio input;
generating a set of structured data based on the text string, the detected indicator of the mental health condition, the speaker, the predefined audio characteristic, and the identified emotion, wherein the generated set of structured data is configured to enable cross-modality search and retrieval of the text string, the speaker, the predefined audio characteristic, and the identified emotion; and
generating a visualization at a display based on the generated set of structured data, wherein the generated visualization comprises an index of a plurality of user selectable keywords, wherein at least one of the plurality of user selectable keywords is associated in the index with the detected indicator of the mental health condition based on a relationship between the at least one keyword and the detected indicator of the mental health condition, and wherein the index is configured to enable search of the structured data based on a keyword of the plurality of user selectable keywords.
|