| CPC G10L 13/08 (2013.01) [G06F 3/0485 (2013.01); G10L 13/02 (2013.01)] | 19 Claims |
|
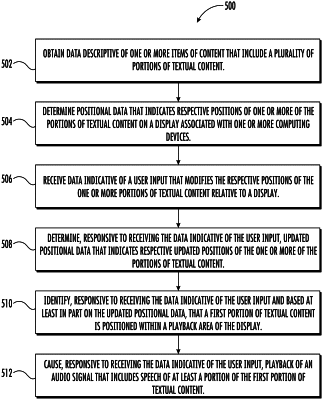
1. A computer-implemented method to perform audio playback of displayed textual content, the method comprising:
obtaining, by one or more computing devices, data descriptive of one or more items of content that include a plurality of portions of textual content;
determining, by the one or more computing devices, positional data that indicates respective positions of one or more of the portions of textual content on a display associated with the one or more computing devices;
receiving, by the one or more computing devices, data indicative of a user input that modifies the respective positions of the one or more of the portions of textual content relative to the display; and
responsive to receiving the data indicative of the user input:
determining, by the one or more computing devices, updated positional data that indicates respective updated positions of the one or more of the portions of textual content;
identifying, by the one or more computing devices and based at least in part on the updated positional data, that a first portion of textual content is positioned within a playback area of the display; and
causing, by the one or more computing devices, playback of an audio signal that includes speech of at least a portion of the first portion of textual content, wherein the speech of at least a portion of the first portion of textual content is determined at least in part using a trained machine learned model.
|