| CPC G06V 30/418 (2022.01) [G06F 40/186 (2020.01); G06V 30/412 (2022.01)] | 22 Claims |
|
1. A computer-implemented method comprising:
programmatically receiving an input electronic document and a first set of candidate templates;
identifying a plurality of attributes from a top-third portion of the input electronic document;
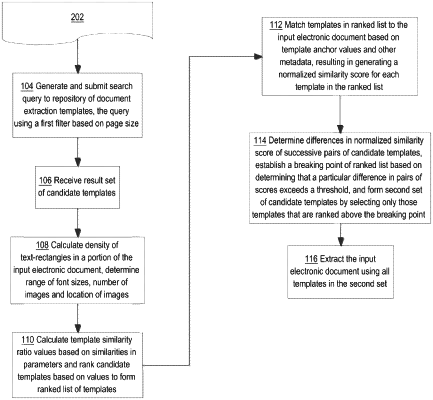
for each particular candidate template from among candidate templates in the first set of candidate templates, calculating a template similarity ratio value that represents a similarity of the particular candidate template to the input electronic document, resulting in digitally storing a plurality of template similarity ratios;
programmatically ranking the candidate templates according to the template similarity ratios;
matching the candidate templates to the input electronic document, resulting in generating a normalized similarity score for each particular candidate template from among the candidate templates;
determining differences in normalized similarity scores of successive pairs of the candidate templates;
when a particular difference in the normalized similarity scores of a particular pair of the candidate templates exceeds a specified threshold value, establishing a breaking point of the candidate templates at the particular pair;
forming a second set of candidate templates by selecting, from among the candidate templates, only those candidate templates that are ranked above the breaking point;
extracting data from the input electronic document using the second set of candidate templates.
|