| CPC G06V 30/412 (2022.01) [G06V 30/18 (2022.01); G06V 30/184 (2022.01); G06V 30/18105 (2022.01); G06V 30/19173 (2022.01); G06V 30/414 (2022.01)] | 20 Claims |
|
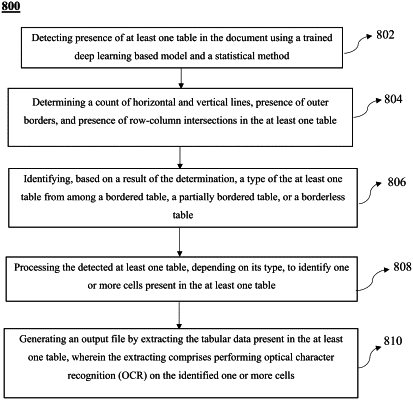
1. A computer implemented method for extracting tabular data present in a document, the method comprising:
detecting presence of at least one table in the document using a trained deep learning based model and a statistical method, wherein for each of the at least one table:
the deep learning based model is adapted to provide a plurality of overlapping table predictions and a plurality of confidence scores corresponding to the plurality of overlapping table predictions, and
the statistical method is adapted to select a single table prediction from the plurality of overlapping table predictions by applying intersection over union on the plurality of confidence scores;
determining a count of horizontal and vertical lines, presence of outer borders, and presence of row-column intersections in the at least one table;
identifying, based on a result of the determination, a type of the at least one table from among a bordered table, a partially bordered table, or a borderless table;
processing the detected at least one table, depending on its type, to identify one or more cells present in the at least one table; and
generating an output file by extracting the tabular data present in the at least one table, wherein the extracting comprises performing optical character recognition (OCR) on the identified one or more cells.
|