| CPC G06V 20/41 (2022.01) [G06V 10/774 (2022.01)] | 20 Claims |
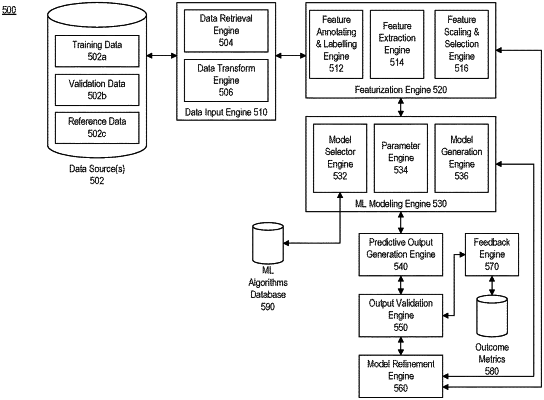
|
1. A method for training a machine learning model to perform automated actions, comprising:
receiving unlabeled digital video data;
generating pseudo-labels for the unlabeled digital video data, the generating comprising:
receiving labeled digital video data;
training a first machine learning model including an inverse dynamics model (IDM) using the labeled digital video data; and
generating at least one pseudo-label for the unlabeled digital video data, wherein:
the at least one pseudo-label is based on a prediction, generated by the IDM, of one or more actions that mimic at least one timestep of the unlabeled digital video data, and
the prediction of the one or more actions is generated based on a non-causal combination of past information and future information within the unlabeled digital video data, the past and future information being relative to one or more reference frames within the unlabeled digital video data;
adding the at least one pseudo-label to the unlabeled digital video data to form pseudo-labeled digital video data; and
further training the first machine learning model or a second machine learning model using the pseudo-labeled digital video data to generate at least one additional pseudo-label for the unlabeled digital video.
|