| CPC G06T 15/205 (2013.01) [G06T 7/70 (2017.01); G06T 19/20 (2013.01); G06T 2207/10024 (2013.01); G06T 2207/20084 (2013.01); G06T 2219/2016 (2013.01)] | 20 Claims |
|
1. A system for reconstructing a scene in three dimensions from a two-dimensional image, the system comprising:
one or more processors; and
a memory communicably coupled to the one or more processors and storing:
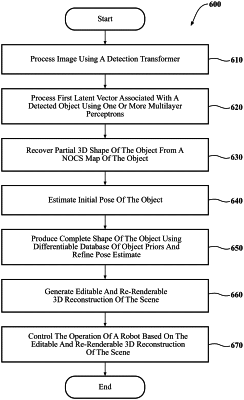
a scene decomposition module including instructions that when executed by the one or more processors cause the one or more processors to process an image using a detection transformer to detect an object in the scene and to generate a first latent vector for the object, a Normalized Object Coordinate Space (NOCS) map of the object, and a depth map for a background portion of the scene;
an object reasoning module including instructions that when executed by the one or more processors cause the one or more processors to process the first latent vector using one or more multilayer perceptrons (MLPs) to produce a second latent vector for the object that represents the object in a differentiable database of object priors, wherein the differentiable database of object priors encodes geometry of the object priors using signed distance fields (SDFs) and appearance of the object priors using luminance fields (LFs);
a three-dimensional (3D) reasoning module including instructions that when executed by the one or more processors cause the one or more processors to:
recover, from the NOCS map of the object, a partial 3D shape of the object;
estimate an initial pose of the object;
fit an object prior in the differentiable database of object priors to align in geometry and appearance with the partial 3D shape of the object to produce a complete shape of the object and refine the initial pose of the object using a surfel-based differentiable renderer to produce a refined estimated pose of the object; and
generate an editable and re-renderable 3D reconstruction of the scene based, at least in part, on the complete shape of the object, the refined estimated pose of the object, and the depth map for the background portion of the scene; and
a control module including instructions that when executed by the one or more processors cause the one or more processors to control operation of a robot based, at least in part, on the editable and re-renderable 3D reconstruction of the scene.
|