| CPC G06T 11/00 (2013.01) [G06N 3/08 (2013.01); G06V 40/168 (2022.01); G06V 40/172 (2022.01)] | 20 Claims |
|
1. A method for image processing, comprising:
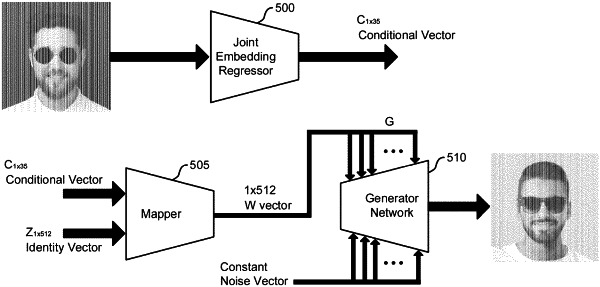
receiving an input image of a face comprising a plurality of input attributes and a plurality of input facial landmarks;
encoding the image to obtain a joint conditional vector representing the plurality of input attributes and the plurality of input facial landmarks using a joint embedding component, wherein the joint conditional vector is an input conditional vector to a mapping component of a generative adversarial network, and wherein the joint embedding component is trained to encode the plurality of input attributes and the plurality of input facial landmarks using an attribute loss based on a one-dimensional attribute vector with a plurality of values corresponding to the plurality of input attributes, respectively, and a landmark loss based on a landmark vector;
generating a latent vector based on the joint conditional vector and an identity vector using the mapping component of the generative adversarial network; and
generating a modified image based on the latent vector using the generative adversarial network.
|