| CPC G06Q 10/1053 (2013.01) [G06F 3/16 (2013.01); H04L 9/3236 (2013.01); H04L 9/50 (2022.05)] | 20 Claims |
|
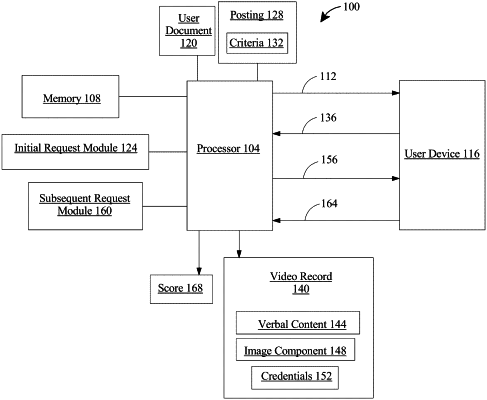
1. An apparatus for creating a video record, the apparatus comprising:
at least a processor communicatively connected to a user device; and
a memory communicatively connected to the processor, the memory containing instructions configuring the at least a processor to:
receive a selection of at least one posting from the user device;
receive a keyword from the user device, wherein the keyword further comprises optical character recognition;
prompt a user with an initial request, wherein prompting the user with an initial request comprises determining the initial request based on the at least one posting, and wherein the determining of the initial request comprising:
iteratively training an initial request machine learning module using initial request training data, wherein the initial request training data correlates at least a keyword input to an initial request output, wherein correlating the at least a keyword input to the initial request output further comprises applying weighted values to the at least a keyword input and correlating the weighed values of the at least a keyword input;
generating, using the trained initial request machine learning module, the initial request based on the at least one posting;
retraining the initial request machine learning module with the updated initial request training data based on the weighted values;
receive an initial response, in video format including speech content comprising an audio and an image recording from the user in response to the initial request;
generate an audio vector, from the initial response, by using frequency coefficients or a spectrogram derived from raw audio samples;
generate an image vector, from the initial response, by implementing image processing for lip reading using a machine learning algorithm;
implement the machine learning algorithm comprising:
training iteratively the machine learning algorithm using a training dataset applied to an input layer of nodes, one or more intermediate layers, and an output layer of nodes by creating one or more connections between the input layer of nodes and the output layer of nodes;
adjusting the one or more connections and one or more weights between nodes in adjacent layers of the machine learning algorithm to iteratively update the output layer of nodes by updating the training dataset applied to the input layer of nodes; and
calculating a weighted sum of the input layer of nodes by adding a bias to the weighted sum of the input layer of nodes;
predict the speech content in the initial response by concatenating the generated image vector and the audio vector;
prompt the user with a subsequent request based on the predicted speech content of the initial response;
receive a subsequent response from the user in response to the subsequent request; and
create a video record as a function of the initial response and the subsequent response, wherein the video record excludes pauses and camera adjustments within the initial response and the subsequent response.
|