| CPC G06N 5/022 (2013.01) [G06F 16/904 (2019.01); G06F 40/103 (2020.01); G06F 40/30 (2020.01); G06N 20/00 (2019.01)] | 19 Claims |
|
1. A system for schematizing content obtained by user, comprising:
at least one processor; and
memory storing instructions that, when executed by the at least one processor, causes the at least one processor to perform a set of operations, the set of operations comprising:
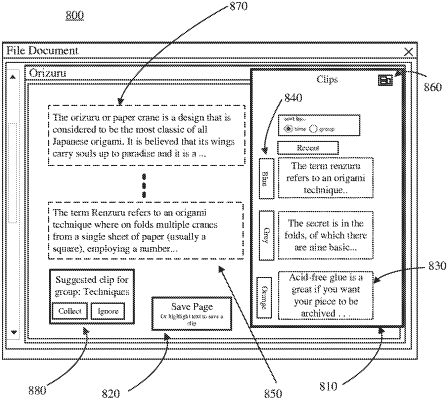
obtaining user behavior data corresponding to a user interaction with a first content;
processing the user behavior data corresponding to the user interaction with the first content to determine a first information unit of the first content associated with a research task;
determining, using a machine learning model configured to derive semantic meaning from content corresponding to the first information unit by processing the user behavior data and the first information unit of the first content according to the machine learning model;
computing a schema intent for the research task, by evaluating the determined semantics associated with the obtained user behavior data and the first information unit of the content, wherein the schema intent is formed based at least in part on a semantic proximity of the first information unit and a second content as determined based at least in part on user input;
processing the schema intent to determine a second information unit, based on a proximity between the first information unit and the second information unit;
computing a schematization map, based on the schema intent for the research task and the proximity between the first information unit and the second information unit;
obtaining a user evaluation input corresponding to the second information unit; and
updating the schematization map based on the user evaluation input.
|