| CPC G06N 3/0455 (2023.01) | 20 Claims |
|
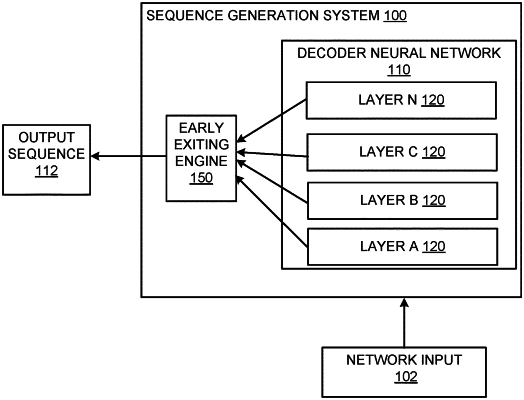
1. A method performed by one or more computers and for auto-regressively generating, using a decoder neural network, an output sequence that includes a respective token from a vocabulary of tokens at each of a plurality of output time steps,
wherein the decoder neural network comprises a sequence of layers,
wherein the decoder neural network is configured to:
receive a respective hidden state for each input in an input sequence comprising a respective input at each of one or more input positions,
process the respective hidden states for the inputs in the input sequence through the sequence of layers to generate a respective updated hidden state for each input in the input sequence, wherein each layer is configured to:
receive a respective input hidden state for each input in the input sequence, and
update the respective input hidden state for each of the inputs at least in part by applying an attention mechanism using the respective input hidden states; and
process the updated hidden state for the last input in the input sequence to generate a probability distribution over the tokens in the vocabulary, and
wherein the method comprises:
for each layer in a subset of the layers in the sequence, maintaining a respective threshold value for each of the plurality of output time steps, wherein two or more of the output time steps have different respective threshold values; and
generating the output sequence by, at each of the plurality of output time steps:
generating a current input sequence from at least the tokens at output time steps that precede the output time step in the output sequence;
generating a respective hidden state for each input in the current input sequence;
processing the respective hidden states for the inputs in the current input sequence through the layers in the sequence of layers until a termination criterion is satisfied, comprising, for each layer starting from the first layer in the sequence and until the termination criterion is satisfied:
receiving a respective input hidden state for the layer for each input in the current input sequence, and
updating the respective input hidden state for each of the inputs in the current input sequence at least in part by applying an attention mechanism using the respective input hidden states;
when the layer is in the subset, generating a confidence score for the layer from at least the updated respective input hidden state for the last input in the current input sequence generated by the layer; and
determining that the termination criterion is satisfied when the confidence score for the layer is greater than or equal to the threshold value for the layer for the output time step;
once the termination criterion is satisfied, processing the updated hidden state for the last input in the current input sequence generated by the layer at which the termination criterion is satisfied to generate a probability distribution over the tokens in the vocabulary; and
selecting the token at the output time step using the probability distribution.
|