| CPC G06F 9/52 (2013.01) [G06F 9/522 (2013.01); G06F 9/542 (2013.01); G06F 15/17318 (2013.01); G06F 15/17325 (2013.01); G06N 3/02 (2013.01); G06N 3/04 (2013.01); G06N 3/08 (2013.01)] | 27 Claims |
|
1. A data processing system comprising a plurality of first processing nodes, each of the plurality of first processing nodes comprising at least one memory configured to store an array of data items, wherein each of the plurality of first processing nodes comprises:
at least one processing unit; and
a gateway device connected to the at least one processing unit, the gateway device configured to interface the plurality of first processing nodes with one another and with a host storage, wherein each of the plurality of first processing nodes belongs to two different sets of processing nodes, wherein a given one of the plurality of first processing nodes is the only processing node that is common to the two different sets of processing nodes to which it belongs, and wherein each of the plurality of first processing nodes is configured to:
take part in a reduce-scatter collective using the respective array of data items to obtain a reduced subset of an array of data items, wherein the reduce-scatter collective is performed between processing nodes of a first one of the respective two different sets of processing nodes, wherein taking part in the reduce-scatter collective is performed by the at least one processing unit of the respective first processing node;
subsequently, exchange the respective reduced subset of the array of data items by participating in an all-reduce collective with processing nodes of a second one of the respective two different sets of processing nodes to which the respective processing node belongs to obtain a further reduced subset of the array of data items, wherein exchanging the respective reduced subset of the array of data items by participating in an all-reduce collective is performed by the gateway device of the respective first processing node; and
subsequently, take part in an all-gather collective using the further reduced subset of the array of data items to obtain a reduced array of data items, wherein the all-gather collective is performed between processing nodes of the first one of the respective two different sets of processing nodes, wherein taking part in the all-gather collective is performed by the at least one processing unit of the respective first processing node,
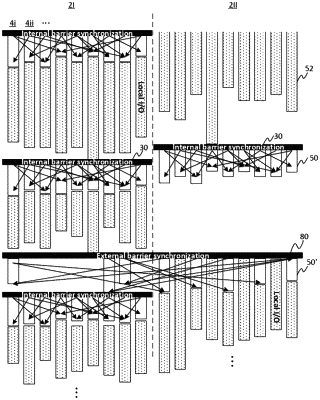
wherein each of the plurality of first processing nodes is configured to execute compute instructions during a compute phase and, following an internal barrier synchronisation, enter an external barrier synchronisation including at least one exchange phase, wherein each of the plurality of first processing nodes is further configured to:
take part in the reduce-scatter collective during the at least one exchange phase;
perform the exchange of the respective reduced subset of the array of data items by participating in the all-reduce collective during the at least one exchange phase; and
take part in the one or more all-gather collectives during the at least one exchange phase.
|