| CPC G06F 9/30036 (2013.01) [G06F 9/3001 (2013.01); G06F 9/30018 (2013.01); G06F 9/30038 (2023.08)] | 19 Claims |
|
1. A processor comprising:
fetch circuitry to fetch a single instruction;
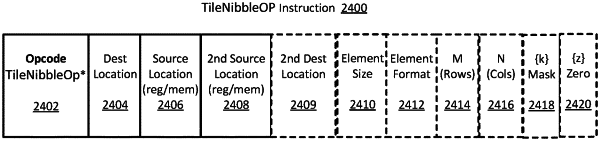
decode circuitry to decode the fetched single instruction having fields to specify an opcode, locations of first source, second source, and destination matrices that are each a single two-dimensional tile register in a matrix operations accelerator of the processor, and that an element size of each element of the first source, the second source, and the destination matrices is larger than a nibble, the opcode to indicate execution circuitry is to cause a grid of fused multiply and accumulate circuits of the matrix operations accelerator to, for each pair of corresponding elements of the first and second source matrices, logically partition each element into nibble-sized partitions, perform an operation indicated by the single instruction on each partition, and store execution results to a corresponding nibble-sized partition of a corresponding element of the destination matrix; and
the execution circuitry to execute the decoded single instruction as per the opcode.
|