| CPC G06F 40/295 (2020.01) [G06F 18/2148 (2023.01); G06F 18/2155 (2023.01); G06F 18/2193 (2023.01); G06F 18/23213 (2023.01); G06N 20/00 (2019.01)] | 20 Claims |
|
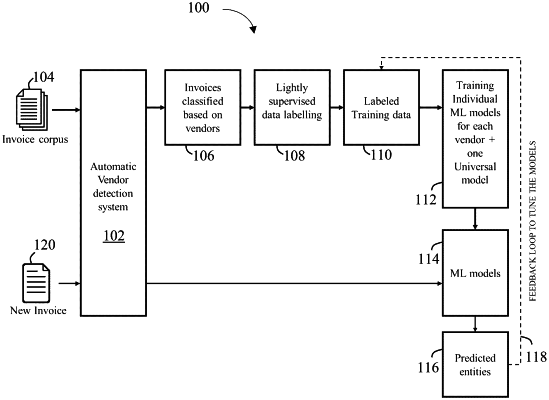
1. A method for training a machine-learning (ML) system, the method comprising:
(a) providing a seed set of labeled entities as a labeled entities set based on a first cluster of a plurality of clusters of documents and using the labeled entities set to train the ML system, to obtain an ML model;
(b) using the trained ML system to predict labels for entities in an unlabeled entities set, yielding a machine-labeled entities set, the prediction providing a respective confidence score for each machine-labeled entity;
(c) selecting from the machine-labeled entities set, a subset of machine-labeled entities having a respective confidence score at least equal to a threshold confidence score;
(d) updating the labeled entities set by adding thereto the selected subset of machine- labeled entities;
(e) removing from the machine-labeled entities set the selected subset of machine-labeled entities and deleting labels assigned to the entities in the updated machine-labeled entities set to provide the unlabeled entities set for a next iteration;
(f) if a termination condition is not reached, repeating steps (a) through (e), and, otherwise, storing the ML model;
(g) selecting a second cluster from the plurality of clusters; and
(h) repeating the steps (a) through (f) for the second cluster to store a different ML model for the second cluster, wherein providing the seed set in step (a) is based on the second cluster.
|