| CPC G06F 40/279 (2020.01) [G06F 16/93 (2019.01); G06F 40/205 (2020.01); G06F 40/30 (2020.01); G06N 3/045 (2023.01); G06N 3/088 (2013.01)] | 19 Claims |
|
1. A method in which one or more processing devices perform operations comprising:
receiving, by a machine learning model trained to generate a search result comprising a document, a search query comprising a text input, wherein the machine learning model is trained by:
receiving pre-training data comprising a plurality of documents; and
pre-training the machine learning model by:
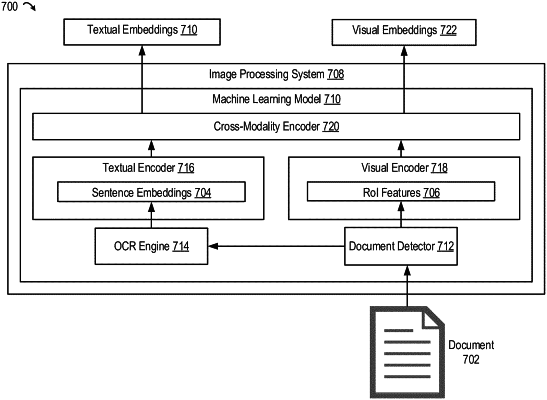
generating, using an encoder, feature embeddings for each of the plurality of documents by applying a masking function to visual features and textual features in each of the plurality of documents, wherein generating the feature embeddings comprises:
generating weighted visual features by applying a first modality-specific attention weight to the visual features;
generating weighted textual features by applying a second modality-specific attention weight to the textual features; and
fusing the weighted visual features and the weighted textual features, wherein fusing the weighted visual features and the weighted textual features comprises multiplying the weighted visual features and the weighted textual features;
generating, using the feature embeddings, output features for each of the plurality of documents by (i) concatenating the feature embeddings and (ii) applying a non-linear mapping to the feature embeddings; and
applying a linear classifier to the output features; and
generating, for display, the search result using the machine learning model by retrieving the search result based on the text input.
|