| CPC G06F 40/279 (2020.01) [G06F 3/0481 (2013.01); G06F 40/109 (2020.01); G06F 40/137 (2020.01); G06F 40/166 (2020.01); G06F 40/232 (2020.01); G06F 40/242 (2020.01); G06F 40/258 (2020.01); G06F 40/284 (2020.01); G06F 40/289 (2020.01); G06V 30/416 (2022.01)] | 7 Claims |
|
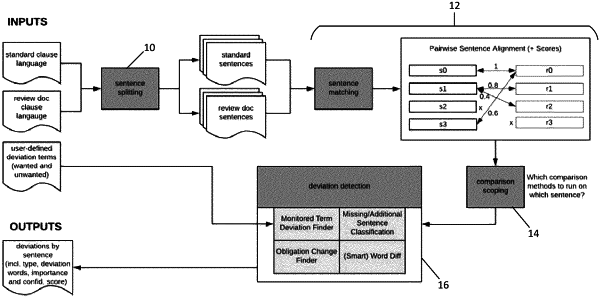
1. A method for extracting information, comprising:
receiving an input text;
splitting the input text into n-grams while retaining a case of words as a feature;
for each n-gram, determining whether it is a capitalized concatenated sequence of words and calculating a frequency of the n-gram's appearance in the input text relative to how rarely the n-gram is used in general use;
in response to a first determination that a particular n-gram is a capitalized concatenated sequence of words and a second determination that the particular n-gram has a relative frequency above a predetermined threshold, identifying the particular n-gram as a defined term from the input text;
identifying a definition of each defined term from the input text; and
displaying the definition of a defined term while also displaying a portion of the input text in which the defined term appears but that is different from a portion of the input text identified as the definition of the defined term.
|