| CPC G06F 30/20 (2020.01) [G06N 5/022 (2013.01); G06N 5/04 (2013.01)] | 8 Claims |
|
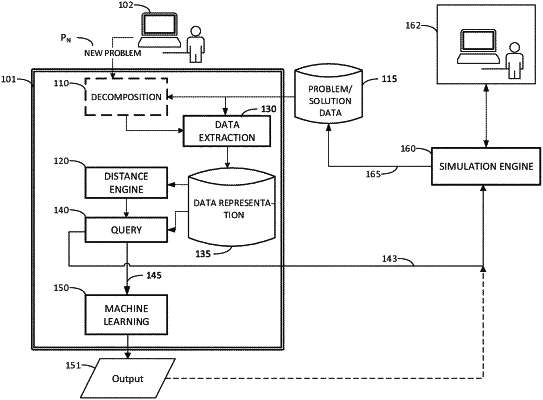
1. A system for accelerated simulation setup for simulating a 3D model of an industrial component, comprising:
a processor; and
a memory having stored thereon instructions executable by the processor, the instructions comprising:
a simulation setup accelerator, comprising:
a data extraction unit configured to:
receive a description of a new problem for simulating the 3D model of an industrial component;
extract input data and output data of previous simulations including simulations of solutions to problems not overtly related to the new problem;
extract textual information from commentary recorded by personnel who conducted one or more of the previous simulations, the textual information relating to assessment of variables and parameters used in the previous simulations;
generate a first data representation of simulation parameters corresponding to the new problem;
generate a plurality of second data representations, each second data representation corresponding to one of the previous simulations based on the extracted input data and output data using an ontological algorithm to represent each solved problem of previous simulations as a node in a graph and weighted edges represent distances between each node, wherein the second data representations are stored efficiently by an autonomous ranking feature;
a distance engine configured to:
quantify similarities, including hidden similarities, between the new problem and the extracted input data and output data based on clustering distances between the first and second data representations and based on the extracted textual information;
a query engine configured to:
formulate a query of the second data representations corresponding to the quantified similarities to determine a candidate problem simulation based on a similarity score; and
a machine learning component configured to:
infer solution outputs for the new problem based on extrapolation or interpolation of outputs of the candidate problem simulation, on a condition that the similarity score is equal to or greater than a threshold for an acceptable match; and
a simulation engine configured to execute the candidate problem simulation for the 3D model on a condition that the similarity score is less than the threshold for an acceptable match, wherein the candidate problem simulation is generated using the query, input variables, and input parameters corresponding to the candidate problem simulation.
|