| CPC G06F 16/313 (2019.01) [G06F 16/335 (2019.01); G06F 16/3334 (2019.01); G06F 16/38 (2019.01); G06N 20/00 (2019.01); G06Q 50/30 (2013.01)] | 20 Claims |
|
1. A computer-implemented method, comprising:
receiving, from a requesting device, a first electronic document specifying natural language text;
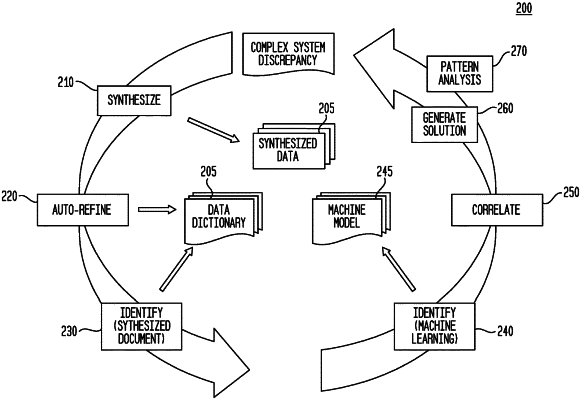
synthesizing the first electronic document to create a second electronic document, the synthesizing comprising:
identifying one or more portions of the first electronic document for filtering, and upon determining that the one or more portions match one or more filtering rules, generating the second electronic document by deleting the one or more portions;
performing an auto-refinement operation on the first electronic document, comprising identifying a first set of terms corresponding to the first electronic document, and including the first set of terms in the second electronic document using a data dictionary structure; and
identifying a second set of terms corresponding to the first electronic document, and including the second set of terms in the second electronic document by determining that terms in the second set of terms match a pattern matching rule;
identifying a first set of electronic documents by searching within a data repository using the second electronic document comprising the first set of terms identified using the data dictionary structure;
inputting the first electronic document to a first machine learning model trained to identify documents in one or more data repositories, and in response to identifying a second set of electronic documents in the data repository using the first machine learning model;
correlating the first set of electronic documents and the second set of electronic documents to generate an aggregated set of electronic documents; and
returning at least one document from the aggregated set of electronic documents to the requesting device.
|