| CPC G06F 16/213 (2019.01) [G06F 40/284 (2020.01); G06F 40/30 (2020.01)] | 9 Claims |
|
1. A processor implemented method for learning-based synthesis of data transformation rules, the method comprising:
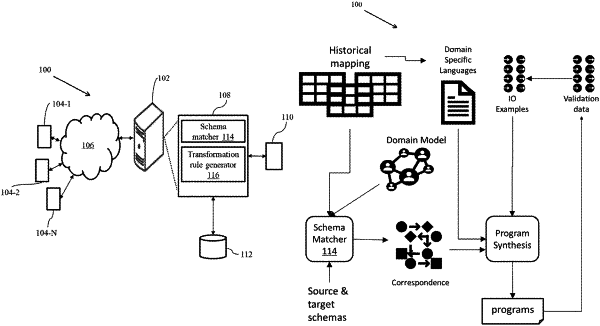
providing, via one or more hardware processors, a source database schema and a target database schema as a first input, wherein the source database schema comprises source tables and respective source fields and the target database schema comprises target tables and respective target fields;
receiving, via the one or more hardware processors, historical data mapping between the source tables and the target tables as a second input, wherein the historical data mapping comprises a plurality of historic transformation rules and a matching list between the source fields and the target fields;
assigning, via the one or more hardware processors, each field from the source fields and the target fields to a semantic type;
categorizing, via the one or more hardware processors, the plurality of historic transformation rules as per the semantic type;
identifying, via the one or more hardware processors, similar rule statements based on structure of operators present therein within each categorized transformation rules and arranging into a plurality of groups;
identifying, via the one or more hardware processors, rule patterns for each of the plurality of groups by replacing field names and constants with a plurality of symbols;
re-arranging, via the one or more hardware processors, the identified rule patterns in a hierarchical order;
identifying and inferring, via the one or more hardware processors, lexical tokens and grammar rules from the hierarchical order;
rearranging, via the one or more hardware processors, the identified lexical tokens and grammar rules to form a set of domain specific languages (DSL), wherein the set of DSLs comprises a plurality of DSL syntactic rules for arrangement of a plurality of DSL operators and their parameters;
defining, via the one or more hardware processors, operator semantics for each of the DSL operator amongst the plurality of DSL operators;
defining, via the one or more hardware processors, operator parameter annotations configured to assist in rule inferencing, for each operator amongst the plurality of DSL operators;
defining, via the one or more hardware processors, a ranking for each of the DSL operator based on a usage frequency count of the plurality of DSL operators from the historical data mapping;
instantiating, via the one or more hardware processors, a synthesizer using
the set of DSLs, the source database schema, the target database schema, a set of source-target data samples, and a matching list between target and source fields, and
a syntax of the DSL operator, defined operator semantics, defined operator parameter annotations and the defined ranking;
generating, via the one or more hardware processors, a plurality of candidate data transformation rules by the synthesizer, wherein the each of generated transformation rules amongst the plurality of candidate data transformation rules are represented as respective programs;
ranking, via the one or more hardware processors, each program using a score assigned to each DSL operator in the set of DSLs, wherein a higher score is assigned to operators which have a higher frequency of use in the historical data mapping as compared to operators which have lower frequency of use; and
selecting, via the one or more hardware processors, a set of candidate data transformation rules out of the plurality of candidate data transformation rules based on a top user-defined number of rankings.
|