| CPC G06F 16/1748 (2019.01) [G06F 16/148 (2019.01); G06F 16/162 (2019.01); G06F 18/22 (2023.01)] | 20 Claims |
|
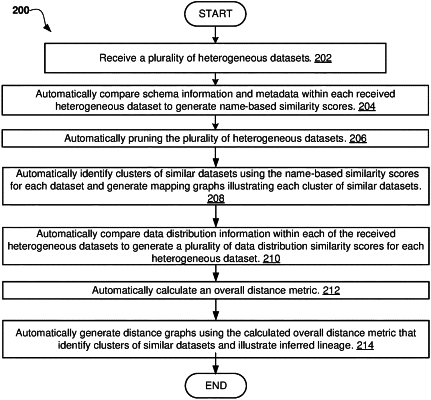
1. A computer-based method of identifying and sorting similar datasets stored within a pool of heterogeneous datasets, the method comprising:
receiving a plurality of heterogeneous datasets;
automatically comparing schema information and metadata within each of the received plurality of heterogeneous datasets to generate name-based similarity scores for each combination of datasets;
automatically pruning the plurality of heterogeneous datasets by removing datasets having no similarities;
automatically identifying clusters of similar datasets using the name-based similarity scores for each dataset and generating mapping graphs illustrating each cluster of similar datasets;
automatically comparing data distribution information within each of the received plurality of heterogeneous datasets to generate a plurality of data distribution similarity scores for each heterogeneous dataset;
automatically calculating an overall distance metric using the name-based similarity scores and plurality of data distribution similarity scores; and
based on the calculated overall distance metric, automatically generating distance graphs, wherein the automatically generated distance graphs identify clusters of similar datasets and illustrate inferred lineage for the clusters of similar datasets.
|