| CPC G06F 16/156 (2019.01) [G06F 16/137 (2019.01); G06F 16/144 (2019.01); G06F 16/182 (2019.01); G06F 16/93 (2019.01); G06F 18/22 (2023.01)] | 32 Claims |
|
1. A method of searching a collection of machines for documents similar to a target document, the method comprising:
at a server system:
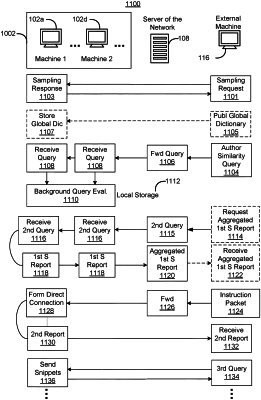
at a sequence of times, requesting samples of document frequency information from respective machines in the collection of machines, and in response receiving sampling responses, wherein
each sampling response in at least a subset of the sampling responses includes information indicating one or more terms in a corpus of information stored at a respective machine in the collection of machines;
collectively, the collection of machines store a corpora of information that includes the corpus of information stored at each respective machine in the collection of machines; and
collectively, information in the sampling responses corresponds, for terms specified in the received sampling responses, to document frequencies of said terms in the corpora of information stored in the collection of machines;
generating a global dictionary from the received sampling responses, the global dictionary includes global document frequency values corresponding to the document frequencies of terms in the corpora of information stored in the collection of machines;
in response to one or more user commands, generating a similarity search query for a target document, the similarity search query including identifiers of terms in the target document, and sending, through one or more linear communication orbits, the similarity search query to one or more respective machines in the collection of machines; and
receiving, in response to the similarity search query:
query responses identifying files stored at the respective machines that meet predefined similarity criteria with respect to the target document, and for each identified file a similarity score that is based, at least in part, on global document frequency values, obtained from the global dictionary, for the terms identified in the similarity search query.
|