| CPC G10L 15/25 (2013.01) [G06V 20/41 (2022.01); G06V 40/161 (2022.01); G06V 40/171 (2022.01); G06V 40/172 (2022.01); G06V 40/20 (2022.01); G10L 15/005 (2013.01); G10L 15/26 (2013.01); B60T 7/22 (2013.01); G06F 16/583 (2019.01); G06F 40/263 (2020.01); H04N 7/15 (2013.01)] | 16 Claims |
|
1. A multilingual speech recognition and translation method for a conference, wherein the conference comprises at least one attendee, and the method comprises:
receiving, at a server, at least one piece of audio data and at least one piece of video data of the at least one attendee from at least one terminal apparatus during the conference;
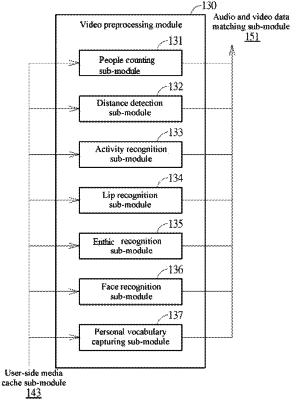
analyzing the at least one piece of video data to generate a first video recognition result and a second video recognition result, wherein the first video recognition result comprises an attendance and an ethnic of the at least one attendee, and the second video recognition result comprises a body movement and a facial movement of the at least one attendee when talking;
generating at least one language family recognition result based on the first video recognition result and the at least one piece of audio data;
splitting the at least one piece of audio data based on the first video recognition result and the second video recognition result to generate a plurality of audio segments corresponding to the at least one attendee;
performing speech recognition on the audio segments according to the at least one language family recognition result to convert the audio segments to a text content;
translating the text content according to the at least one language family recognition result; and
transmitting the translated text content for displaying on the at least one terminal apparatus;
wherein the method further comprises:
determining a quantity of speakers and a speaking time of each speaker according to a distance, in the at least one piece of video data, between the at least one attendee and a microphone to generate the second video recognition result; and
obtaining the plurality of audio segments according to the second video recognition result.
|