| CPC G10L 15/22 (2013.01) [G06F 3/16 (2013.01); G06F 16/24578 (2019.01); G06F 16/635 (2019.01); G06F 16/686 (2019.01); G10L 15/26 (2013.01); G10L 15/30 (2013.01); G10L 2015/223 (2013.01); G10L 2015/227 (2013.01); G10L 2015/228 (2013.01)] | 20 Claims |
|
1. One or more non-transitory computer-readable storage media storing instructions that, upon execution on a system, cause the system to perform operations comprising:
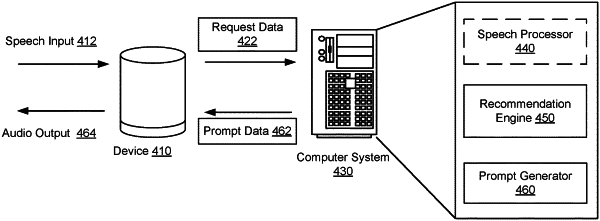
receiving, from a user device over a data network, first audio data corresponding to a speech input and indicating a request for music playback, the user device associated with a user account;
generating text data based at least in part on the first audio data;
determining a value associated with the request based at least in part on the text data;
determining a user feature of the user account, a context feature of a context of the request, and a metadata feature of metadata of music content;
determining, from a data store, a recommendation for the music content;
determining, from the data store, the metadata;
determining a customization rule that uses a decay function to limit a total number of features that can be included in customization data, the decay function allowing to exclude a first feature used within a number of prompts ago and allowing to include a second feature used outside of the number of prompts ago;
selecting, based at least in part on the customization rule, a feature from at least one of the user feature, the context feature, or the metadata feature by at least determining that a history of using the feature indicates lack of use of the feature in a most recent prompt;
generating, based at least in part on the history, the customization data that comprises the feature;
generating prompt data that comprises an acknowledgement of the speech input and the customization data; and
sending the prompt data and a command to the user device over the data network, the command causing the user device to generate second audio data from the prompt data and to output the second audio data prior to outputting the music content.
|