| CPC G06V 20/62 (2022.01) [G06F 18/213 (2023.01); G06N 3/045 (2023.01); G06V 10/40 (2022.01); G06V 10/95 (2022.01); G06V 30/10 (2022.01)] | 19 Claims |
|
1. A method of multi-directional scene text recognition based on multi-element attention mechanism, comprising:
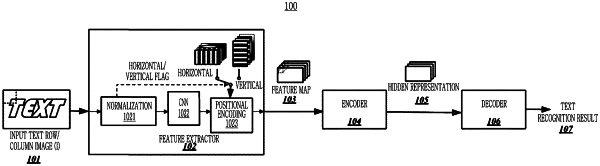
performing, by a feature extractor, normalization processing for a text row/column image I output from an external text detection module;
extracting, by the feature extractor, a feature for the normalized image by using a deep convolutional neural network to acquire an initial feature map F0;
adding, by the feature extractor, a 2-dimensional directional positional encoding P to the initial feature map F0 in order to output a multi-channel feature map F, wherein the size of the feature map F is HF×WF, and a number of channels is D;
modeling, by an encoder, each element of the feature map F output from the feature extractor as a vertex of a graph;
converting, by the encoder, the multi-channel feature map F into a hidden representation H through designing a local adjacency matrix, a neighboring adjacency matrix, and a global adjacency matrix for the graph and implementing multi-element attention mechanisms of local, neighboring, and global; and
converting, by a decoder, the hidden representation H output from the encoder into recognized text and setting the recognized text as the output result,
wherein the encoder,
is constituted by two identical encoding unit stacks, and each encoding unit includes a local attention module MEALocal, a neighboring attention module MEANeighbor, and a global attention module MEAGlobal, and a feed forward network module, and
decomposes the elements of the multi-channel feature map F to a vector according to column order, and obtains a feature matrix X, and the dimension of the feature matrix X is N×D, i.e., an N-row and D-column matrix, the N represents the number of elements of each channel, N=HF×WF, and D represents the number of channels of the feature map F.
|