| CPC G06F 16/288 (2019.01) [G06F 40/295 (2020.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06Q 10/10 (2013.01); G06Q 30/0201 (2013.01); G06Q 40/03 (2023.01)] | 20 Claims |
|
11. A method for using a computer tool to automatically generate predictions associated with interdependence detection between a plurality of data objects based on receiving unstructured text, each data object of the plurality of data objects corresponding to an entity name, the method comprising:
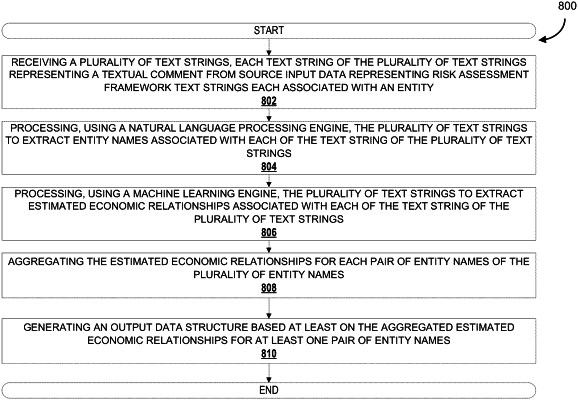
receiving a plurality of text strings, each text string of the plurality of text strings representing a textual comment from source input data representing risk assessment framework text strings each associated with an entity;
processing, using a natural language processing engine, the plurality of text strings to extract entity names associated with each of the text string of the plurality of text strings;
processing, using a machine learning engine, the plurality of text strings to extract estimated economic relationships associated with each of the text string of the plurality of text strings, the estimated economic relationships identified between at least two different entity names;
aggregating the estimated economic relationships for each pair of entity names of the plurality of entity names, the aggregated estimated economic relationships indicative of potential interdependence between the pair of entity names; and
generating an output data structure based at least on the aggregated estimated economic relationships for at least one pair of entity names, the output data structure including a data object having linkages between the at least one pair of entity names to form a group of connected counterparties;
wherein the machine learning engine converts portions of the plurality of text strings representing the extracted estimated economic relationships into vector representations, the estimated economic relationships extracted from numerical tokens extracted from the plurality of text strings, the estimated economic relationships stored as additional rows or columns in an expanded representation of the source input data associated with an economic relationship label, a confidence level, and a list of feature words;
wherein the vector representations are pre-processed during generation to stem words to root forms of the words, to remove stop words, and to remove words that either appear often in the text or rarely in the text;
wherein the vector representations are based at least on term frequency—inverse document frequency representations having at least a first portion representing a term frequency indicative of how often a word appears in a comment text string and a second portion representing a document frequency which is determined by dividing a total number of comments divided by how many comments the word appears in and conducting a natural logarithm of results of the division; and
wherein a hyperparameter for generating the term frequency—inverse document frequency representations is optimized by the machine learning engine.
|