| CPC G06F 16/285 (2019.01) [G06F 16/2255 (2019.01)] | 8 Claims |
|
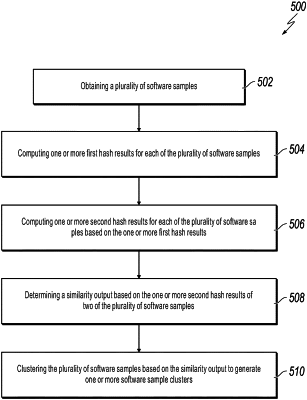
1. A computer-implemented method, comprising:
obtaining, by a server, a plurality of software samples;
computing, by the server, a plurality of first hash results for each of the plurality of software samples by disassembling each of the plurality of software samples to obtain a plurality of functions in the respective software sample and performing a first hashing for each of the plurality of obtained functions to obtain the plurality of first hash results, wherein each first hash result corresponds to a respective obtained function in a respective software sample;
computing, by the server, one or more second hash results for each of the plurality of software samples based on the plurality of first hash results by performing, for each software sample, a second hashing for the plurality of first hash results of the respective software sample to generate the one or more second hash results of the respective software sample, wherein an amount of the one or more second hash results is less than an amount of the plurality of first hash results;
grouping the plurality of software samples into a plurality of stride subgroups based on the second hash results of the plurality of software samples, wherein the grouping the plurality of software samples into the plurality of stride subgroups based on the second hash results comprises:
comparing the second hash result of each of the plurality of software samples; and
grouping two software samples that share at least one same second hash result into a same stride subgroup, wherein in each of the plurality of stride subgroups, each software sample in the respective stride subgroup shares at least one same second hash result;
determining, by the server, a similarity output based on the one or more second hash results of two of the plurality of software samples in a same stride subgroup;
clustering, by the server, the plurality of software samples based on the similarity output to generate one or more software sample clusters; and
detecting malware samples by using the one or more software sample clusters.
|