| CPC G06F 16/245 (2019.01) [G06F 3/0482 (2013.01); G06F 3/0486 (2013.01); G06F 8/10 (2013.01); G06F 8/35 (2013.01); G06F 8/71 (2013.01); G06F 8/77 (2013.01); G06F 9/5005 (2013.01); G06F 11/3438 (2013.01); G06F 16/248 (2019.01); G06Q 10/0637 (2013.01); G06Q 10/101 (2013.01); H04L 67/133 (2022.05)] | 19 Claims |
|
1. A method comprising:
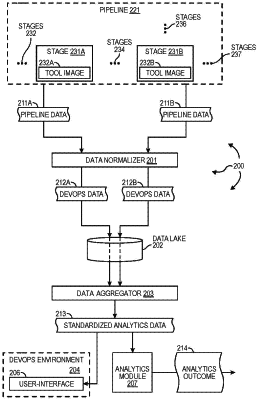
executing a pipeline including a first tool and a second tool, the first tool and the second tool being wrapped in a flexible schema model configured to correlate tool-level data from the first tool and the second tool into a pipeline schema;
receiving pipeline data including: (1) first pipeline data in a first format resulting from execution of a first tool running on first resources, the first pipeline data received through a first API tailored to the first tool and (2) second pipeline data in a second format resulting from execution of a second tool running on second resources, the second pipeline data received through a second API tailored to the second tool, the second format differing from the first format;
filtering, validating, normalizing, sequencing, contextualizing, and aggregating first DevOps data from the first pipeline data;
storing the first DevOps data in a data lake in raw form along with a first step summary according to the flexible schema model;
filtering, validating, normalizing, sequencing, contextualizing, and aggregating second DevOps data from the second pipeline data;
storing the second DevOps data in the data lake in raw form along with a second step summary according to the flexible schema model;
aggregating the first DevOps data and the second DevOps data from the data lake into standardized analytics data including normalizing and serializing the first DevOps data and the second DevOps data into in an analytics format compatible with a client analytics environment, wherein normalizing and serializing the first DevOps data and the second DevOps data into in the analytics format comprises converting the first pipeline data and the second pipeline data into the pipeline schema;
presenting the standardized analytics data in a client DevOps environment providing unified insights into client pipeline operation; and
performing a client analytics operation using the standardized analytics data.
|