| CPC G06V 30/416 (2022.01) [G06N 20/00 (2019.01); G06V 30/414 (2022.01)] | 18 Claims |
|
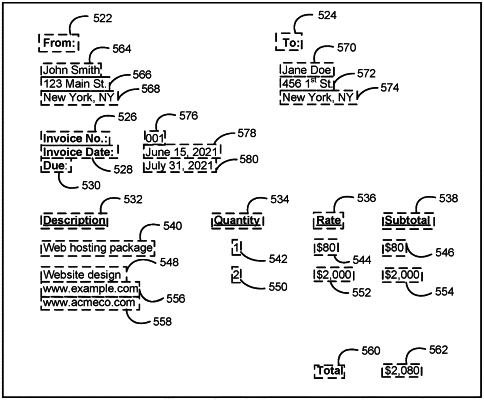
1. A computer-implemented method for extracting data from a document, the method comprising:
determining a first set of features associated with the document, wherein the first set of features comprises a set of region proposals that bound one or more portions of text within the document;
applying a first machine learning model to the first set of features to generate a set of predictions comprising a set of scores associated with one or more key-value pairs, wherein the set of scores includes, for each region proposal in the set of region proposals, a first score that represents a probability that the region proposal includes text associated with a single key in the one or more key-value pair, a second score that represents a probability that the region proposal includes text associated with a single value in the one or more key-value pairs, and a third score that represents a probability that the region proposal includes text that is unrepresentative of any single key or any single value in the one or more key-value pairs; and
extracting the one or more key-value pairs from the document based on the set of predictions.
|