| CPC G06Q 20/401 (2013.01) [G06Q 20/382 (2013.01); G06Q 20/389 (2013.01)] | 20 Claims |
|
1. A system, comprising:
a non-transitory memory; and
one or more hardware processors coupled with the non-transitory memory and configured to read instructions from the non-transitory memory to cause the system to perform operations comprising:
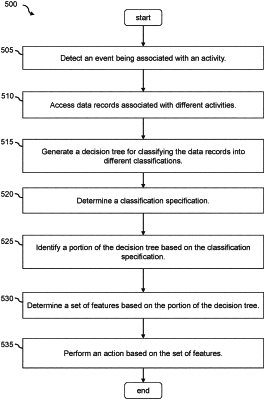
detecting an occurrence of an anomaly in association with a transaction;
obtaining a plurality of data records associated with a plurality of transactions, wherein each data record in the plurality of the data records corresponds to a corresponding transaction and comprises (i) attribute values corresponding to a plurality of attributes and (ii) a label indicating whether the anomaly has occurred for the corresponding transaction;
generating a decision tree configured to predict occurrences of the anomaly based on the plurality of data records, wherein the decision tree comprises a plurality of nodes, and wherein each node in the plurality of nodes corresponds to a condition associated with an attribute from the plurality of attributes;
feeding the plurality of data records through the decision tree;
determining, for each node of the plurality of nodes in the decision tree, characteristics of data records from the plurality of data records that pass through the node;
pruning a first portion of the decision tree based on first characteristics of first data records from the plurality of data records that pass through the first portion of the decision tree satisfying a set of criteria;
identifying a set of attributes corresponding to one or more nodes within a second portion of the decision tree; and
configuring a classification engine to use the set of attributes as input features for detecting occurrences of the anomaly in transactions.
|