| CPC G06N 3/084 (2013.01) [G06N 3/04 (2013.01); G06N 3/08 (2013.01)] | 10 Claims |
|
1. An integrated circuit (IC) chip for backpropagation in a fully connected layer of a neural network, comprising:
a controller circuit configured to receive an instruction; and
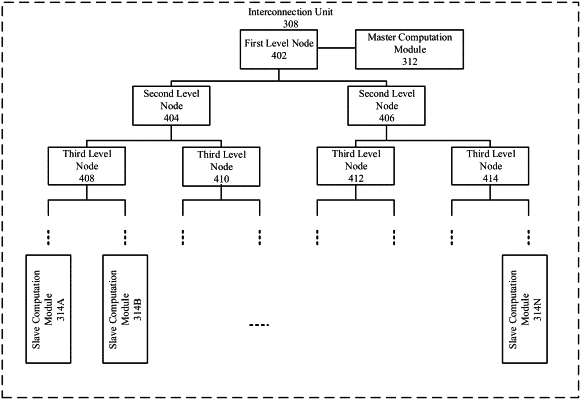
one or more computation circuits that include:
a master computation circuit,
one or more slave computation circuits, and
an interconnection circuit communicatively connected to the master computation circuit and the one or more slave computation circuits,
wherein the master computation circuit configured to
receive input data and one or more first data gradients in response to the instruction, and
transmit the input data and the one or more first data gradients to the one or more slave computation circuits, and
wherein the one or more slave computation circuits are respectively configured to multiply one of the one or more first data gradients with the input data to generate a default weight gradient vector,
wherein the master computation circuit is further configured to update one or more weight values based on the default weight gradient vector,
wherein the master computation circuit is further configured to apply a derivative of an activation function to the one or more first data gradients to generate one or more input gradients,
wherein the one or more slave computation circuits are respectively configured to multiply one of the one or more input gradients with one or more weight vectors in a weight matrix to generate one or more multiplication results, and
wherein the interconnection circuit is configured to combine the one or more multiplication results of a lower dimension into an output gradient vector of a higher dimension.
|