| CPC G06F 9/54 (2013.01) [G06F 9/5027 (2013.01); G06F 18/214 (2023.01); G06N 3/04 (2013.01); G06N 3/063 (2013.01)] | 27 Claims |
|
1. A method comprising:
extracting a model from a neural network description;
determining accelerator configuration information usable to configure a deep learning accelerator to provide a trained model that is in accordance with the extracted model;
evaluating one or more results of the determining in accordance with one or more predetermined cost criteria to produce one or more goal-evaluation metrics;
conditionally altering one or more meta-parameters that the determining is based at least in part on wherein the conditionally altering is dependent on at least one of the one or more goal-evaluation metrics being less than a respective predetermined threshold;
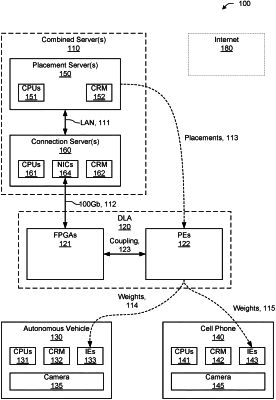
wherein the deep learning accelerator comprises a fabric and a plurality of processing elements enabled to communicate packets with each other via the fabric in accordance with a plurality of communication pathways identifiable by respective virtual channel identifiers;
wherein the plurality of processing elements is a plurality of logical processing elements, a target wafer comprises a plurality of physical processing elements each having a respective physical location in a context of the target wafer, and each of the plurality of logical processing elements has a correspondence to a respective one of the plurality of physical processing elements; and
wherein the determining the accelerator configuration information comprises assigning computations associated with respective nodes of the extracted model to respective portions of the plurality of logical processing elements in accordance with the respective physical locations.
|