| CPC G06F 40/211 (2020.01) [G06F 40/109 (2020.01); G06F 40/30 (2020.01); G06N 3/08 (2013.01)] | 18 Claims |
|
7. An electronic device, comprising:
at least one processor; and
a memory communicatively coupled to the at least one processor; wherein,
the memory is configured to store instructions executable by the at least one processor, when the instructions are executed by the at least one processor, the at least one processor is enabled to perform:
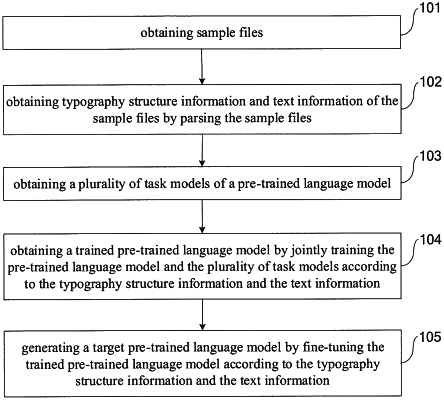
obtaining sample files;
obtaining typography structure information and text information of the sample files by parsing the sample files;
obtaining a plurality of task models of a pre-trained language model, wherein the plurality of task models comprise a first prediction model, a masked language model and a second prediction model;
obtaining a trained pre-trained language model by jointly training the pre-trained language model and the plurality of task models according to the typography structure information and the text information; and
generating a target pre-trained language model by fine-tuning the trained pre-trained language model according to the typography structure information and the text information.
|