| CPC G06F 16/22 (2019.01) [G06F 16/21 (2019.01); G06F 3/0604 (2013.01); G06F 3/0655 (2013.01); G06F 3/0679 (2013.01)] | 20 Claims |
|
1. A non-transitory machine-readable medium storing a program executable by at least one processing unit of a device, the program comprising sets of instructions for:
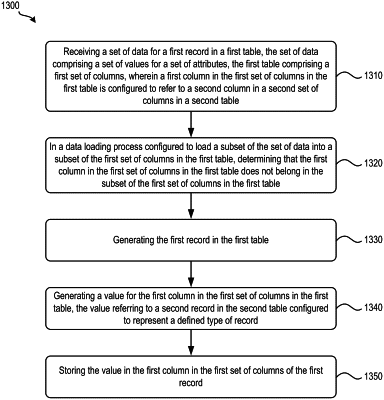
receiving a set of data for loading data into a record in a first table, the set of data comprising a set of values for a set of attributes, the first table comprising a first set of columns, wherein a first column in the first set of columns in the first table is configured to refer to a second column in a second set of columns in a second table, wherein the first table is a fact table and the second table is a dimension table;
generating the record in the first table;
generating a value for the first column in the first set of columns of the record in the first table based on a subset of the set of values for a subset of the set of attributes, wherein the first column corresponds to a dimension attribute of the set of attributes, wherein the value serves as a reference to a record in the second table; and
storing the value in the first column in the first set of columns of the record and not storing a value of the set of values for the set of attributes corresponding to the dimension attribute in the record,
wherein the second column in the second set of columns of the record in the second table is generated, independently of the value for the first column of the record in the first table, based on at least one dimension value of the record in the second table using a same algorithm for generating the value for the first column of the record in the first table.
|