|
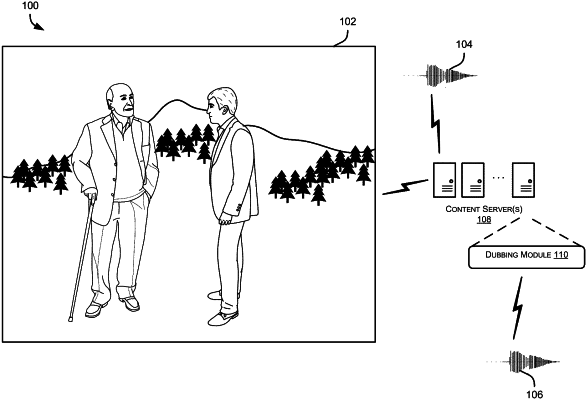
1. A method comprising: receiving first audio data associated with a first performance in a first language; dividing the first audio data into a plurality of audio clips; determining, using a processor, a voice identity score for an audio clip of the plurality of audio clips by using an autoencoder configured to minimize a reconstruction loss between a first output of the autoencoder and a randomly selected audio clip of the plurality of audio clips; determining a voice identity embedding for the first performance based on the voice identity score; generating second audio data by translating the first audio data from the first language into a second language, wherein translating the first audio data comprises using a machine learning model that implements the voice identity embedding of the autoencoder to preserve the voice identity; determining a performance characteristic score of the second audio data by using a twin neural network trained using contrastive learning based on a first training set and a second training set, wherein: the first training set comprises third audio data including positive examples; and the second training set comprises fourth audio data including negative examples, the negative examples identified based on the fourth audio data being temporally misaligned or the fourth audio data having an altered performance characteristic; and determining, using the processor, a loss based on a second output of the machine learning model and the performance characteristic score; and iteratively re-generating the second audio data, using the machine learning model, based on the loss.
|