| CPC G10L 21/0208 (2013.01) [G06N 3/045 (2023.01); H04M 9/082 (2013.01); G10L 2021/02082 (2013.01); G10L 2021/02166 (2013.01)] | 20 Claims |
|
1. A system, comprising:
one or more computing devices;
wherein the one or more computing devices include instructions that upon execution on or across the one or more computing devices:
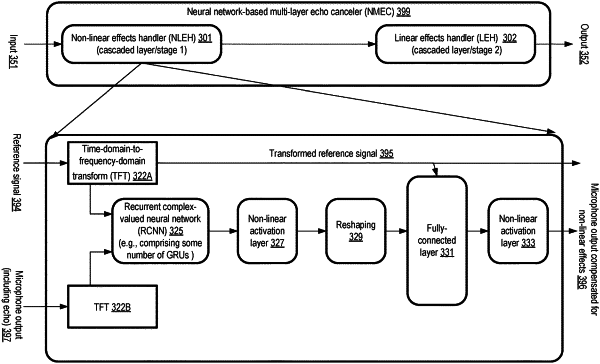
obtain, as input at a neural network-based multi-layer echo canceler comprising a first layer which includes a non-linear effects handler and a second layer which includes a linear effects handler, (a) output of a first microphone in a first communication environment comprising one or more microphones and one or more speakers, and (b) a reference signal received at the first communication environment from a second communication environment and directed to a first speaker of the one or more speakers;
generate, at the non-linear effects handler, a first output obtained at least in part by applying a first learned compensation for a first set of properties of the output of the first microphone, wherein the first set of properties includes (a) a first non-linearity resulting from a clock skew between the first speaker and the first microphone, and (b) a second non-linearity in an audio reproduction capability of the first speaker, wherein applying the first learned compensation comprises modifying one or more weights of a first neural network based at least in part on processing of the reference signal and the output of the first microphone;
provide, as input to the linear effects handler, at least the output of the non-linear effects handler;
generate, at the linear effects handler, a second output obtained at least in part by applying a second learned compensation for a second set of properties of the output of the non-linear effects handler, wherein the second set of properties includes a first echo resulting from capturing audio output of the first speaker at the first microphone, and wherein applying the second learned compensation comprises utilizing, at a second neural network, a learned linear model of an acoustic path between the first speaker and the first microphone; and
transmit the second output to the second communication environment.
|