| CPC G10L 17/06 (2013.01) [G06F 17/16 (2013.01); G06N 3/04 (2013.01); G10L 17/02 (2013.01); G10L 17/18 (2013.01); G10L 25/18 (2013.01); G10L 25/24 (2013.01); G10L 25/78 (2013.01)] | 15 Claims |
|
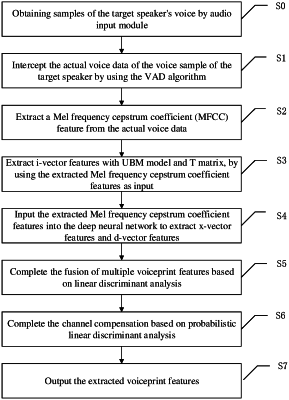
1. A method for fusing voiceprint features, comprising:
acquiring at least two voiceprint features of a voice sample of a target speaker; and
fusing the at least two voiceprint features based on a linear discriminant analysis,
wherein acquiring the at least two voiceprint features of the voice sample of the target speaker comprises:
acquiring a voice spectrum feature of the voice sample of the target speaker;
extracting an i-vector voiceprint feature by using a universal background model and a total variability space matrix and using the voice spectrum feature as an input; and
extracting an x-vector voiceprint feature and a d-vector voiceprint feature by using a deep neural network, and
wherein extracting the x-vector voiceprint feature and the d-vector voiceprint feature by using the deep neural network, comprises:
adding a pooling layer to the deep neural network, calculating an average value of the pooling layer, continuing to propagate forward, and extracting an activation value of a subsequent intermediate layer as the x-vector voiceprint feature; and
extracting an activation value from a last hidden layer of the deep neural network, and then acquiring the d-vector voiceprint feature by accumulating and calculating an average value of the activation value.
|