| CPC G10L 15/16 (2013.01) [G06N 3/044 (2023.01); G06N 3/063 (2013.01); G10L 15/02 (2013.01); G10L 15/083 (2013.01); G10L 15/22 (2013.01); G10L 25/18 (2013.01); G10L 25/21 (2013.01); G10L 25/30 (2013.01); G10L 25/51 (2013.01); G10L 2015/227 (2013.01)] | 16 Claims |
|
1. A system comprising:
a processor;
a memory coupled to the processor, wherein the memory comprises a computer-readable instructions in form of a voice-based conversational artificial intelligence (AI) platform comprising:
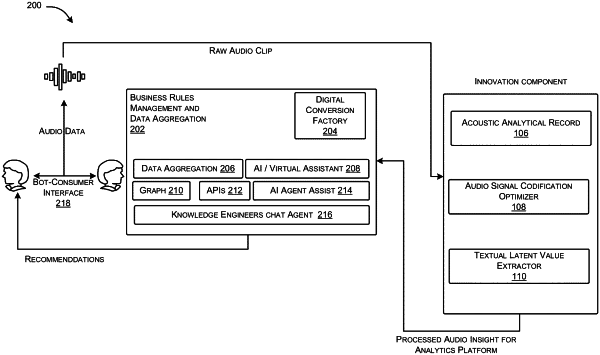
an acoustic analytical record engine operatively coupled with the processor that causes the engine to:
receive an audio sample comprising a plurality of audio signals indicative of voice conversation between a user and a bot;
convert the audio signals into quantifiable and machine-ingestible power spectrum indicators and acoustic indicators that uniquely represent the audio sample, to create a feature vector;
an audio signal codification optimizer coupled with said processor that causes the optimizer to:
determine likelihood of an attribute value representing the audio sample based on the power spectrum indicators and the acoustic indicators by generating a convolutional neural network model for each attribute category;
establish user persona attribute values across one or more attribute categories for the received audio sample based on the estimated likelihood; and
a textual latent value extractor coupled with said processor that causes the optimizer to:
generate textual transcript based on the audio sample; and
analyze the textual transcript using a hybrid deep learning engine that analyzes textual content in the textual transcript and evaluate interactions in the content to determine associated polarities coupled with latent intents, wherein the textual content in the transcript is analyzed to generate token vector representations that are fed into a bi-directional LSTM neural network to determine the associated polarities; and
wherein the user persona attribute values, associated polarities, latent intents, correspond to insights, and wherein the insights are fed back to at least one of the acoustic analytical record engine, the audio signal codification optimizer, and the textual latent value extractor.
|