| CPC G10L 15/063 (2013.01) [G10L 15/16 (2013.01); G10L 25/24 (2013.01)] | 19 Claims |
|
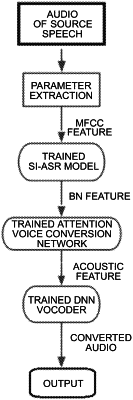
1. A voice conversion system, comprising:
a speaker-independent automatic speech recognition model, comprising at least a bottleneck layer, configured to: convert a mel-scale frequency cepstral coefficients feature of an inputted source speech into a bottleneck feature of the source speech through the bottleneck layer, and output the bottleneck feature of the source speech to an Attention voice conversion network through the bottleneck layer;
where a training method for the speaker-independent automatic speech recognition model comprises:
inputting a number of a character encoding to which a word in a multi-speaker speech recognition training corpus is converted, together with a mel-scale frequency cepstral coefficients feature of the multi-speaker speech recognition training corpus, to the speaker-independent automatic speech recognition model; executing a backward propagation algorithm; and performing iterative optimization until the speaker-independent automatic speech recognition model is converged;
the Attention voice conversion network configured to convert the bottleneck feature of the source speech into a mel-scale frequency cepstral coefficients feature in conformity with a target speech; and
a neural network vocoder configured to convert the mel-scale frequency cepstral coefficients feature in conformity with the target speech into and output audio.
|